
The AI Data Readiness Lessons From Mayo and JPMorgan
Companies delivering real AI outcomes in 2026 share one trait: they ran an AI readiness assessment before choosing a model and made data a board-level priority.
Only 7% of enterprises say their data is completely ready for AI, even as investment in models continues to grow.
Companies delivering real AI outcomes start with an AI readiness assessment before selecting a model or vendor.
Leading enterprises scaled AI by fixing three core data issues first: ownership, fragmentation, and governance.
Every 13 seconds, somewhere around the world, a Rolls-Royce-powered aircraft is taking off or landing. Each one is a data generator. A single Airbus A350 carries 6,000 sensors producing 2.5 terabytes of data every day. Multiply that across thousands of engines, dozens of airlines, and global maintenance networks, and the data problem becomes unmanageable fast.
The issue was never a shortage of data. It was that the data was fragmented, inconsistently formatted, and siloed across systems that were never designed to communicate. No enterprise AI strategy could fix that by selecting a better model. The foundation underneath was broken.
So before scaling AI, Rolls-Royce launched its IntelligentEngine vision in 2018, connecting product engineering, aftermarket services, and digital systems into a single operational framework.
Service intervals extended by 25%. Up to 95% of used engine materials are now recovered and recycled. TotalCare, its power-by-the-hour service model, aligned Rolls-Royce's revenue directly with airline performance.
"The IntelligentEngine is really about bringing our computing capability and data together to enhance value for our customers."
—Phil Curnock, Chief Engineer, Civil Future Programs, Rolls-Royce
Most enterprises are still trying to scale AI on broken foundations that lack AI-ready data. Rolls-Royce solved that problem before it became one.
Which raises the question every data leader is now asking: What is an AI readiness assessment? It is the process of evaluating whether an organization's AI-ready data, integration, and governance can actually support AI before deployment begins.
In this article, we’ll look at how three leading enterprises each confronted a distinct AI data readiness failure and the specific fix that moved them from pilot to production.
Why AI-Ready Data Is the Gap Most Enterprise AI Strategies Never Close
Enterprise AI strategy is accelerating. New models are entering the market faster than most organizations can evaluate them. Similarly, enterprise AI platforms are also expanding across operations, analytics, customer service, and internal workflows.
But beneath that momentum, the foundation supporting those systems remains fragmented.
The gap shows up in outcomes first. Only 7% of enterprises say their data is completely AI-ready. Meanwhile, nearly 60% of AI projects are expected to be abandoned this year because organizations still lack AI-ready data foundations. Even among deployed initiatives, only 28% of AI use cases in infrastructure and operations achieve expected ROI outcomes, while 20% fail outright.
These numbers point to the same structural problem. Most enterprises are still trying to scale AI across fragmented data environments that were never built for it.
“Taken together, these findings expose a critical disconnect between where organizations want to be with AI and where they actually stand."
—Sergio Gago, CTO, Cloudera
That disconnect becomes more visible as AI moves deeper into business-critical operations. Systems that perform well in isolated pilots often struggle when they depend on data that moves consistently across departments, platforms, and environments. This is exactly what an AI readiness assessment helps identify before deployment starts, rather than after problems arise.
The infrastructure gaps are also already becoming visible. Nearly 79% of organizations say limited access to data across environments is slowing AI initiatives. At the same time, only 30% report that their data sources are fully integrated across the business.
Rolls-Royce confronted the same challenge long before AI data readiness became an enterprise priority. Building Engine Health Monitoring required consolidating operational data across fleets, maintenance workflows, and airline partners.
Most enterprises are still avoiding that work today. The ones that aren't are now seeing measurable AI outcomes. They fixed the data foundation before they scaled the models.
The Three Data Failures that Keep Enterprise AI Stuck in Pilot Mode
While most enterprises can point to a successful AI pilot, very few can explain why it never scaled. Even among organizations that invested heavily in modern enterprise AI platforms, 56% still lack full access to their own data. The problem isn't the pilot. It's what sits underneath it.
Here are three major structural problems an AI readiness assessment uncovers before deployment:
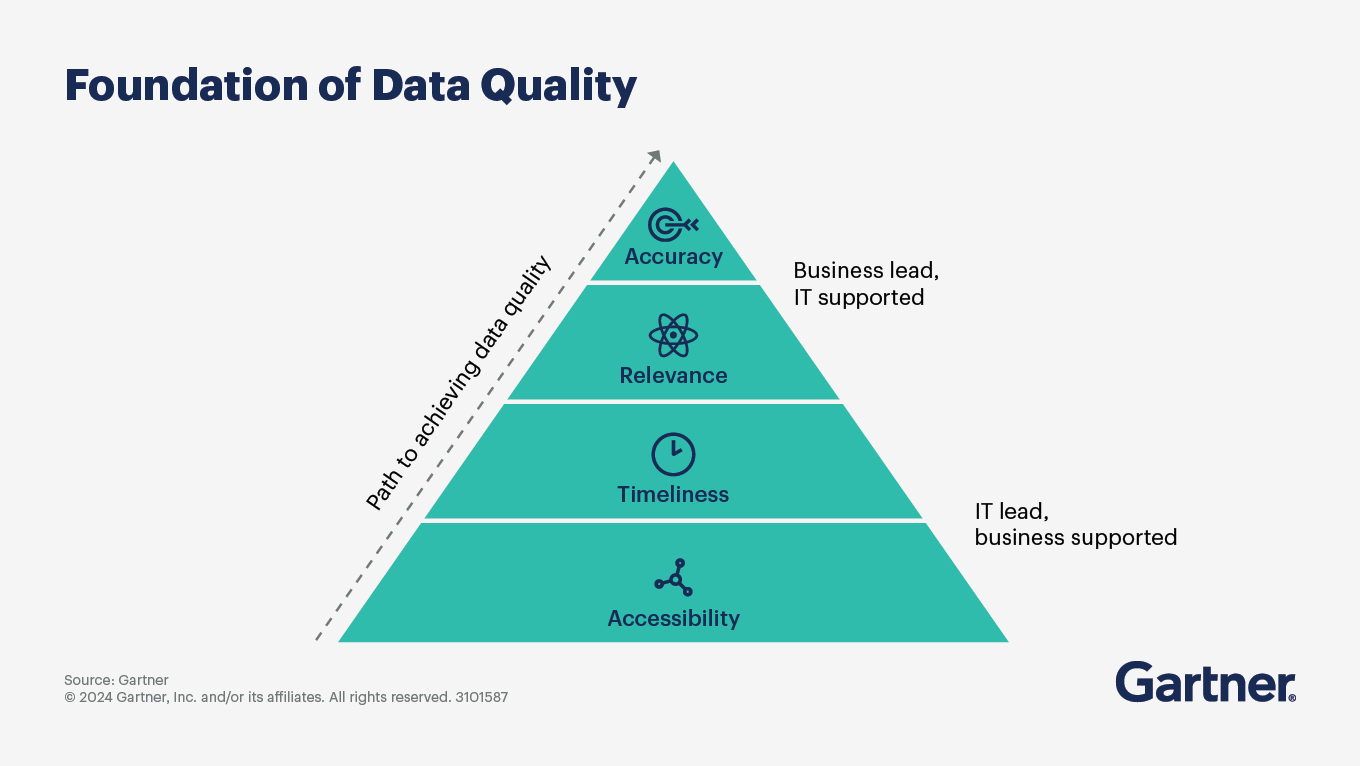
- Data Quality Being Owned by the Wrong Teams: In many enterprises, data quality is still treated as a technical responsibility rather than an operational one. Business teams understand how the data is created and used, but remediation cycles often sit with centralized IT teams. The result is slow feedback loops, delayed fixes, and deployment bottlenecks that compound as AI systems scale. Poor data quality already costs organizations an average of $12.9 million annually, and those costs rise when ownership remains fragmented. For example, Gartner’s data quality pyramid divides ownership into two parts. IT teams are responsible for making data accessible and timely. Business teams, however, are responsible for ensuring the data is relevant and accurate. These are the layers enterprise AI tools depend on the most.
- Fragmentation Left Intact: Most enterprises still operate across disconnected SaaS platforms, legacy systems, regional databases, and business-unit-specific environments. As AI systems expand, those silos don't shrink. Models begin operating on incomplete or inconsistent information. The average enterprise runs 897 applications, and only 29% are connected, leaving data spread across fragmented systems instead of a unified environment. AI scaled across that infrastructure can’t deliver consistent outcomes because it is working from incomplete sources of truth. No enterprise AI strategy can deliver consistent outcomes amid that fragmentation.
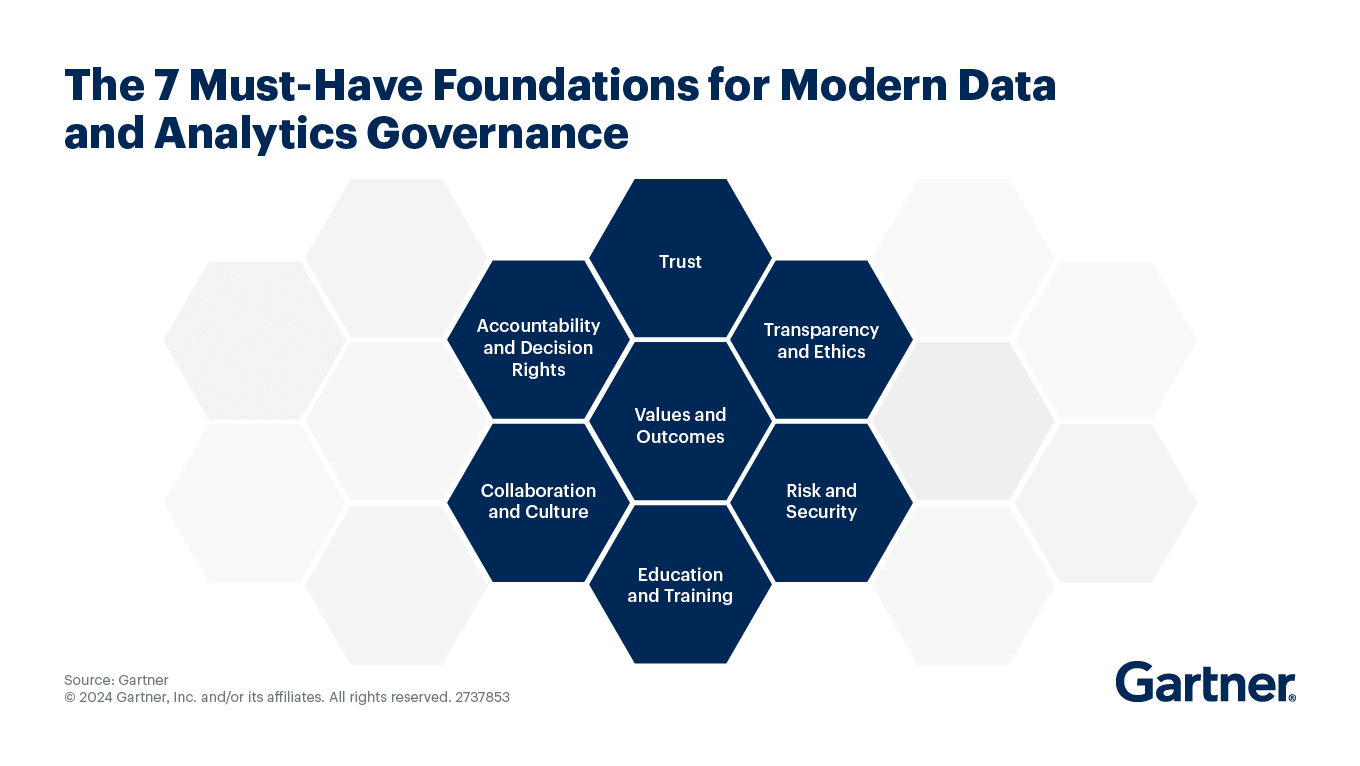
- Governance Disconnected from Leadership: Data governance still sits outside core business leadership in many organizations, treated primarily as a compliance or technical function. Without executive ownership, standardized definitions, and auditability across pipelines, AI-ready data can’t be reliable or compliant at scale. By 2027, 60% of organizations are projected to miss AI value targets because governance frameworks remain fragmented or unclear. Gartner's seven foundations for modern data and analytics governance show what it actually takes to close that gap: values and outcomes at the center, supported by trust, accountability, transparency, and risk management. Most enterprises never get there because governance never leaves the compliance team.
Next, let's walk through three enterprises that each addressed one of the structural problems an AI readiness assessment uncovers before deployment and the single decision that moved them from pilot to production.
Mayo Clinic Passed Its AI Readiness Assessment by Fixing Data Ownership First
When data quality is owned by the wrong teams, the backlog builds faster than any central team can clear it. For Mayo Clinic, that ceiling arrived in 2022. The organization’s AI data readiness depended on building the right structural foundation across the business.
The organization had 76,000 staff and 7,300 physicians across campuses in Minnesota, Arizona, and Florida. Demand for AI use cases was rising across diagnostics, operations, and patient care. But every use case had to move through a central CDAO (Chief Data and Analytics Officer) team of around 60 people.
Clinicians who understood the data best had no ownership over it. The backlog kept growing. The team couldn’t keep up. Mayo Clinic solved it by changing who owned the data.
Business and clinical teams became responsible for integrating, preparing, and maintaining their own data inside the organization's shared ecosystem. The CDAO team moved into an enablement role. It maintained the data library, metadata, and clinical rules while supporting teams building AI in their own domains.
Mayo Clinic also built its AI Factory on Google Vertex AI. It became one of the most clinician-focused enterprise AI platforms in healthcare, allowing doctors and medical teams to build AI applications directly within their own practice area.
"AI is a tool that needs to be put in the hands of the people with deep knowledge in the practice. If you want to leverage AI, the people with the domain knowledge need to be able to leverage the tools."
—Ajai Sehgal, CDAO, Mayo Clinic
The results followed the ownership. Researchers created an FDA-cleared algorithm capable of detecting heart pump problems from ECG readings. The surgical practice independently funded its own data and analytics team, starting with data preparation before any AI development began.
Meanwhile, governance didn’t disappear. It moved closer to the people using the data every day. In other words, Mayo Clinic passed its AI data readiness challenge by giving data ownership to the people who understood it best. That shift is what made scale possible.
Starbucks Ran an AI Data Readiness Fix Before Deploying Deep Brew
Fragmented data doesn’t announce itself. It shows up as a disconnect between what a system recommends and what a store can actually deliver. For Starbucks, that gap was the constraint sitting underneath 41,000 stores across 87 markets.
Every mobile order, payment, loyalty interaction, and inventory update was generating data. But that data lived across systems built at different times for different functions. The mobile app, point-of-sale (POS) systems, loyalty infrastructure, and supply chain weren’t working from the same source of truth.
The issue wasn’t collecting more data. It was making the existing data work together. Starbucks needed to solve its AI data readiness problem before any model could be trusted to act on it.
Before scaling AI use cases, Starbucks built its data foundation around three priorities: data quality, trusted access, and impact measurement across the business. Leadership treated data alignment as an operational priority tied directly to customer experience and store execution, not just an engineering initiative.
That foundation became the backbone for Deep Brew, Starbucks' enterprise AI platform built on Microsoft Azure. Deep Brew integrates transaction history, behavioral signals, inventory, location, and store operations into a single shared intelligence layer. It doesn’t just personalize the app. It connects personalization to what the store can actually deliver.
"Our recent Deep Brew enhancements allow us to deploy new artificial intelligence and machine learning in weeks instead of months to unlock value faster."
—Deb Hall Lefevre, CTO, Starbucks
The same data baseline supports various other store operations. For instance, Green Dot Assist delivers real-time guidance to baristas through in-store tablets on drink recipes, customizations, and equipment issues.
Similarly, developed with NomadGo, AI-powered inventory monitoring using computer vision and augmented reality now counts inventory eight times more frequently, giving stores real-time visibility and faster replenishment.
By FY2025, Starbucks reported stronger Rewards engagement and higher member spend. Machine learning personalization became one of the company's ten priority AI initiatives. In 2025, Starbucks also began integrating fan-created customized drinks directly into the mobile app after identifying ordering patterns across Rewards data.
The system works because every customer, operational, and inventory signal flows through the same unified layer. Starbucks didn’t scale AI and then fix fragmentation. It built an AI-ready data infrastructure first and scaled everything on top of it.
JPMorgan's AI Readiness Assessment is a Board-Level Decision
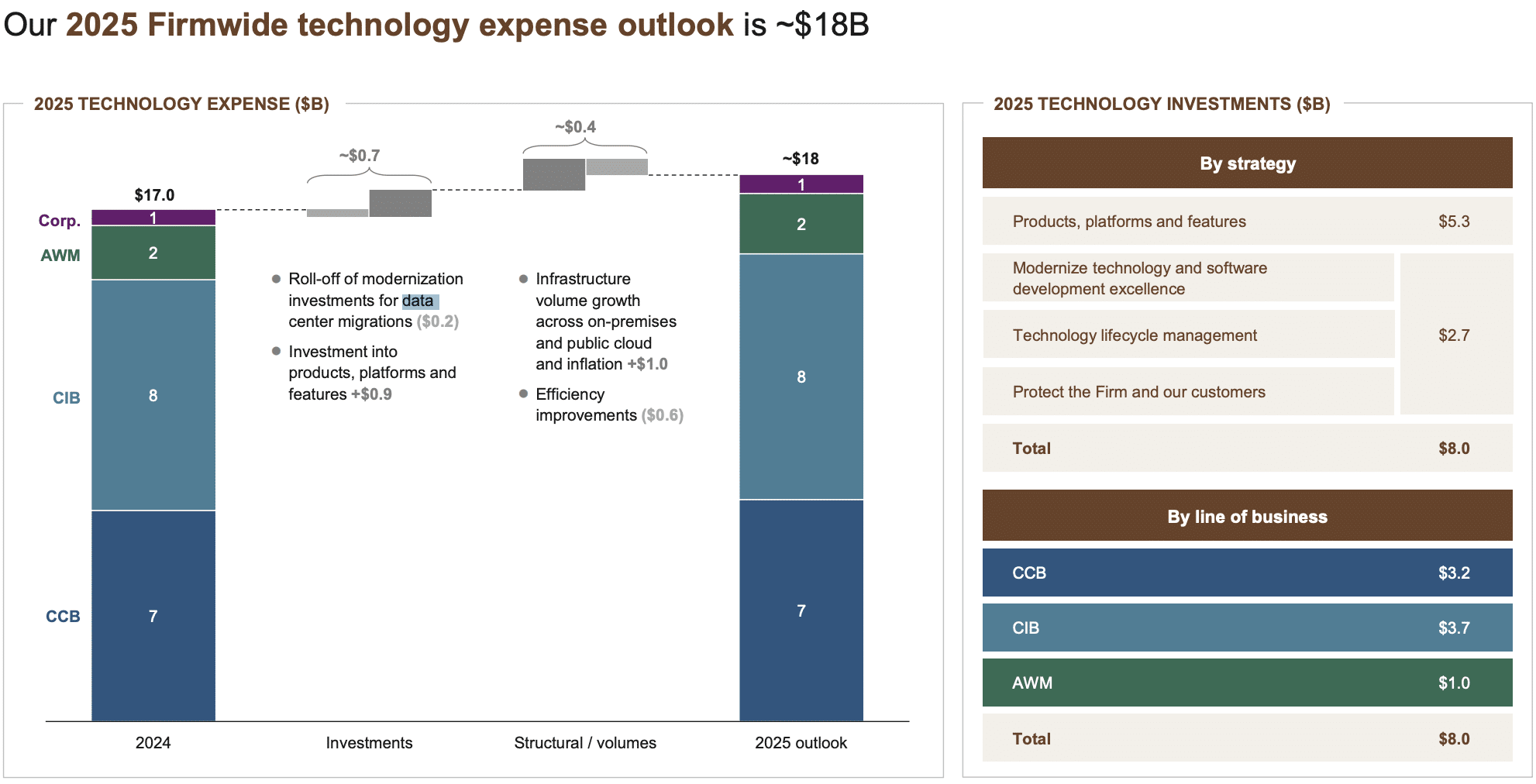
At JPMorgan Chase, the challenge was far from a lack of investment. According to JPMorgan Chase's 2025 firmwide technology expense outlook, the company committed approximately $18 billion to technology that year, allocated across consumer banking, commercial and investment banking, and asset and wealth management. The breakdown shows where the firm placed its bets: products and platforms, infrastructure modernization, and technology lifecycle management. JPMorgan also ranked highest on the Evident AI Index for banking AI maturity.
The real issue was governance. Data standards, risk controls, and lineage varied across business units. No single executive owned the problem firmwide. Without governance embedded at the leadership level, an enterprise AI strategy couldn’t produce consistent, reliable outputs across the firm.
At JPMorgan's scale, governance disconnected from leadership created compliance risk and capped what AI could do. The solution was structural. In the "Update on Specific Issues Facing Our Company" section of JPMorgan Chase's 2023 Annual Report, under the subheading "The Critical Impact of Artificial Intelligence," Jamie Dimon, Chairman and Chief Executive Officer, announced that he was moving governance into the room where business decisions are made by creating a Chief Data and Analytics Officer role elevated directly to the Operating Committee, reporting directly to him and COO Daniel Pinto.
Dimon stated that elevating this role to the Operating Committee reflected how critical the function would be going forward and would embed data and analytics into decision-making at every level of the company.
That structure shaped every deployment that followed. Teresa Heitsenrether was appointed CDAO to lead firmwide governance and data strategy. All data initiatives were consolidated under Mark Birkhead, the Firmwide Chief Data Officer, with a focus on ensuring data is published in formats that large language models can understand.
The LLM Suite was built entirely in-house to maintain governance, regulatory compliance, and control over sensitive financial data. External tools, including ChatGPT, were restricted for internal use. Ethicists, data scientists, engineers, and risk professionals were embedded into deployment decisions before systems scaled.
"Safeguarding and governance give the license to do more with data."
—Mark Birkhead, Firmwide Chief Data Officer, JPMorgan Chase
JPMorgan delivered $1.5 billion in business value from AI in 2023. Its LLM Suite reached 200,000 employees, the largest enterprise AI tools deployment on Wall Street. More than 450 AI use cases are in production across operations, client services, and risk management, with plans to reach 1,000 by the end of 2026. These results were possible because governance was designed in from the start.
JPMorgan's AI didn’t scale because the models were better. It scaled because governance moved from the compliance team to the operating committee. Once governance became a leadership mandate rather than a technical function, it stopped being a constraint on enterprise AI strategy. It became the infrastructure that made AI deployable across the entire firm.
An AI Readiness Assessment Matters More Than the Model You Choose
When Rolls-Royce committed to IntelligentEngine, the decision looked like an engineering initiative. In practice, it was an AI readiness assessment decision. The foundation came first. The intelligence followed because the data was ready to support it.
That is what separates enterprises delivering measurable AI outcomes from those still running pilots. The difference is rarely the technology. Every CTO and CDO building an enterprise AI strategy in 2026 faces the same question: not which model to choose next, but whether your organization's AI data readiness is strong enough to deliver on whatever enterprise AI tools and platforms you deploy.
.avif)
Frequent Asked Questions
How do you ensure data is AI-ready?
Ensuring data is AI-ready starts with ownership, infrastructure, and governance before deployment begins. Mayo Clinic gave clinicians ownership of the data they used, Starbucks unified fragmented systems through Deep Brew, and JPMorgan Chase moved governance to the Operating Committee before scaling AI firmwide. That sequence helped these companies expand AI across hundreds of production use cases while many enterprises still struggle with fragmented data environments.
What are enterprise AI platforms?
Enterprise AI platforms connect data, models, governance, and business workflows into a unified system that allows AI to scale across the organization. Starbucks’ Deep Brew platform powers personalization and operational AI across more than 41,000 stores by connecting customer, inventory, and operational data into one intelligence layer. Mayo Clinic’s AI Factory similarly enabled clinicians to scale more than 200 active AI projects across the organization.
What is an enterprise AI model?
An enterprise AI model is designed to operate within an organization’s own data environment, governance standards, and operational workflows. JPMorgan Chase built its internal LLM Suite to maintain control over financial data and regulatory compliance, while Rolls-Royce built Engine Health Monitoring systems around connected operational data from airlines and maintenance networks. These models depend on reliable infrastructure underneath them to scale effectively.
What does it mean to have AI-ready data?
AI-ready data is accurate, integrated across systems, and governed with clear ownership so AI models can produce reliable outputs across the business. Starbucks addressed fragmented operational and customer data through Deep Brew, connecting loyalty signals, transactions, inventory, and store operations across more than 41,000 locations. Mayo Clinic solved the ownership side by giving clinicians stewardship of the data they understood best.
What is an example of enterprise AI?
JPMorgan Chase’s LLM Suite is one of the clearest examples of enterprise AI at scale, supporting 200,000 employees and more than 450 AI use cases across the business. The company elevated data governance to the Operating Committee before AI deployments scaled, helping deliver $1.5 billion in AI business value in a single year. The system was built around governed infrastructure rather than isolated AI tools.
What is an AI readiness assessment?
An AI readiness assessment evaluates whether an organization’s data quality, integration, and governance are strong enough to support AI at scale before deployment begins. Only 7% of enterprises say their data is fully ready for AI, while nearly 60% of AI projects are expected to be abandoned due to an unprepared data foundation for enterprise deployment. Rolls-Royce addressed this years earlier by building the IntelligentEngine infrastructure to standardize and connect engine data across its fleet.



.svg)






_0000_Layer-2.png)

