
Inside How Rolls-Royce and BMW Took AI From Pilot to Production
88% of AI pilots fail before production, and it starts with scoping. See how Rolls-Royce, BMW, and JPMorgan Chase solved the gaps that bottleneck enterprise AI deployment.
88% of enterprise AI implementations never reach production; the common failure point is the scoping stage, not launch.
Data gaps, workflow misfit, and a lack of governance tend to kill proof-of-concept programs before they reach production.
With the right underlying structure, BMW's AI quality inspector reduced defect detection time on a line that builds a new vehicle every 57 seconds.
A large regional hospital system spends eight months building an AI tool to generate clinical progress notes from physician dictation. When the implementation team runs the pilot, the numbers look strong. Documentation time drops, and participating physicians rate the tool highly, so leadership approves full deployment.
Six months later, under a third of the staff are using the system. The friction stems from the difference between how a motivated, closely supervised volunteer cohort uses the tool and how the rest of the organization actually works. The physicians who were not in the cohort have different habits, different levels of comfort with the interface, and different expectations. And while the notes the model generates are accurate, they land in the wrong place in the hospital’s interface; retrieving them requires manual copy-paste, a step no one flagged during the controlled pilot.
The pilot was declared a success, yet the rollout failed.
This outcome is far from an anomaly. According to research conducted by IDC, 88% of enterprise AI proofs of concept never reach production. Most organizations read that number as a deployment problem, but the data shows it is a design problem that originates when pilots are scoped. Organizations that reach production and succeed define what operational success looks like, who owns it, and what monitoring is required before the pilot begins, rather than after it stalls. Here, we’ll see how three organizations across varied industries treated production as the design requirement, not the finish line, and succeeded.
Why Do Enterprise AI Implementations Fail?
Enterprise AI implementation challenges are typically diagnosed too late and in the wrong place. By the time a pilot stalls, the organization is already having the wrong conversation, debating model performance or vendor choice, when the failure originated in how the pilot was scoped. Research consistently shows that most AI failures are organizational, not technical, a finding that’s echoed in the case studies below.
Three main issues account for most failed enterprise AI deployments. Understanding them is the starting point for building an AI strategy that scales to production.
- Data Readiness. Pilots are routinely built on data that performs well in a demo environment and breaks under production conditions. Inconsistent labeling, missing fields, and operational definitions that vary by team go undetected until the model is running against live data.
- Workflow Integration. A model that performs accurately in isolation frequently fails when it encounters the actual sequence of steps humans follow to complete a task. Enterprise AI implementation best practices consistently identify this as the most underestimated gap and the one most likely to kill a pilot that looked successful in testing.
- Production Control. Even pilot programs that survive deployment frequently collapse within months. Without drift monitoring, defined ownership, and governance infrastructure established before launch, models degrade. PwC's AI observability research found that organizations operating without production monitoring have limited visibility into whether their AI systems are performing as intended, identifying system behavior, system health, user access, and data flow as key dimensions. Often, problems are discovered only after business outcomes have degraded.
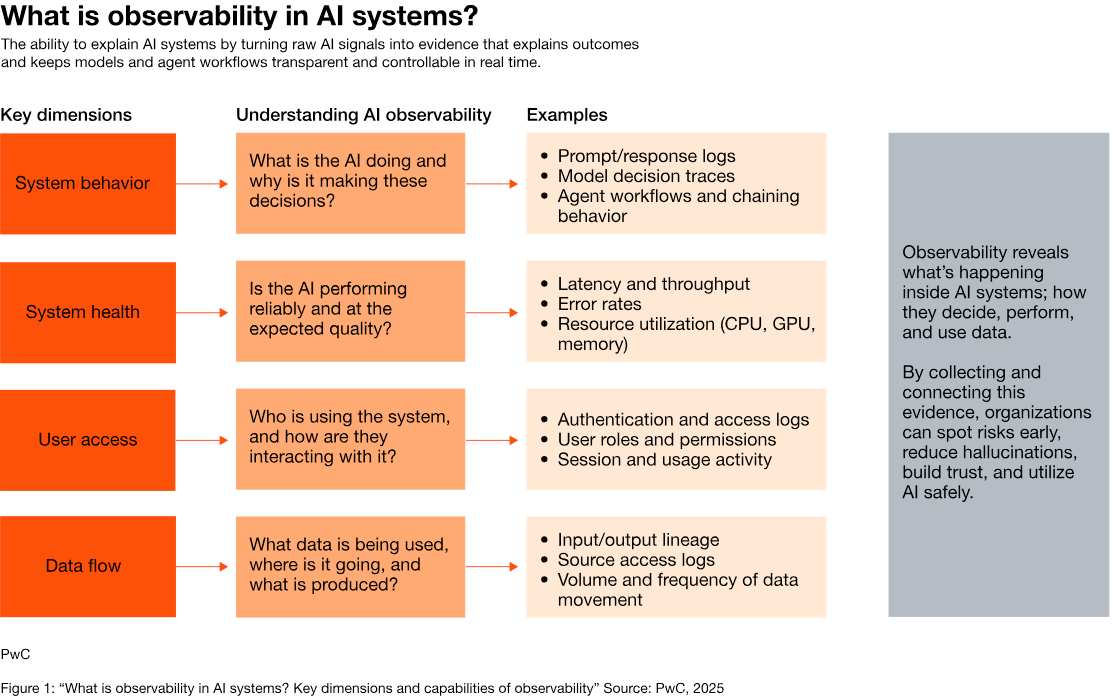
These issues compound. But the organizations that reach production avoid this sequence altogether, treating each issue as a pre-launch design requirement.
Rolls-Royce Addresses Data Readiness in Aerospace Manufacturing
Rolls-Royce had a data problem before it had an AI problem. The company's IntelligentEngine program, launched in 2018, set out to use AI modeling to predict real-time component usage and engine lifetime across its Trent engine fleet. The ambition was sound, but the data infrastructure was not ready for it.
Data on engine use came from airline customers, who periodically extracted information from their own systems and uploaded spreadsheets. The feeds were delayed, inconsistent, and impossible to model against in real time. "Predictive maintenance models are all backwards looking," explains Rob Mather, Vice President of Aerospace and Defense Industries at IFS, which partnered with Rolls-Royce to solve the problem.
To get there, Rolls-Royce needed a different foundation. The company worked with IFS to build an automated data pipeline that delivers real-time in-service engine status directly from airline customers into Rolls-Royce systems. The pipeline integrates sensor data, flight conditions, component configuration, and maintenance history into a unified feed that AI models can run against. Rolls-Royce also built a central data repository using Microsoft Cloud for Manufacturing to standardize how data flows across its design, build, and operate functions.
Rolls-Royce increased machine usage by 30%, accelerated fault resolution from days to near real-time, and now detects and prevents around 400 unplanned maintenance events annually, saving millions in repair costs.
"By embracing Microsoft AI and digital technologies, we will develop efficient and fully utilized smart factories, whilst enhancing our customer and employee experience."
—Kaveh Pourteymour, Group Chief Digital Information Officer at Rolls-Royce
Rolls-Royce did not begin building predictive models and then ask where the data would come from. It solved the data problem first, under production conditions, and built AI on top of a foundation that could hold it.
BMW Solves Workflow Integration on the Factory Floor
At BMW Group's Plant Regensburg, a new vehicle rolls off the assembly line every 57 seconds. Each one is built to individual customer specifications, and virtually no two vehicles are alike. That variability made traditional quality inspection a bottleneck: static checklists could not keep pace with the volume or the complexity.
BMW's answer, developed in collaboration with Munich startup Datagon AI, was an AI system called GenAI4Q, launched as a pilot project in April 2025. The system generates a tailored inspection catalog for each specific vehicle, drawing on both vehicle configuration data and real-time production data to determine the scope and sequence of checks required. What made it work was the interface.

Rather than asking inspectors to log into a separate system or change how they moved through the floor, BMW surfaced GenAI4Q's recommendations through a smartphone app that inspectors already carried. The AI organized the inspection in the right order, within the tool the operator was already using.
That design decision is the enterprise AI implementation lesson. BMW built its model based on how inspectors actually worked and designed the AI to fit inside that reality. "The use of artificial intelligence supports the digital transformation of BMW Group production towards an intelligently connected factory," said Armin Ebner, head of BMW Group Plant Regensburg. Plant Regensburg was named Factory of the Year 2024 in the category of excellent large-series assembly.
Enterprise AI implementations that scale treat workflow design as seriously as model design. The difference is almost always whether the people doing the work were considered before the system was built, not after.
JPMorgan Chase Maintains Production Control at Scale
JPMorgan Chase confronted a version of the production control gap that most enterprises face as their AI portfolios grow. Models built by different teams used different feature definitions. Deployment pipelines varied by business line. There was no standardized monitoring, no consistent governance framework, and no centralized visibility into how models were performing after launch. In a heavily regulated financial environment, that fragmentation was a compliance liability.
The bank's answer was OmniAI, an internal machine-learning platform built by the Chief Technology Office to standardize the end-to-end AI lifecycle across all lines of business. JPMorgan describes the platform's core purpose as prerequisites for operating at scale in a regulated environment. When OmniAI launched, it supported a handful of early testers running a single capability: single-node model training.
What made that scale possible was governance built into the infrastructure before deployment. OmniAI enforces model risk tiering, classifying models by consequence level and applying different approval and monitoring requirements at each tier. It includes automated drift detection, a kill-switch capability that can decommission a degrading model immediately, and mandatory model cards that document what each model does, what data it uses, and what guardrails are in place. These controls are requirements embedded in the platform itself.
The production results are significant. Fraud detection enabled by OmniAI has produced loss prevention exceeding $1 billion annually, with more than 450 use cases currently running in production. That scale is possible because the bank built infrastructure that made sustained enterprise AI deployment governable, the kind of distinction that determines whether an organization runs a portfolio of pilots or a production AI program.
How to Scale AI from Pilot to Production
The three case studies above each address a different gap, but the underlying principle is consistent: organizations that reach production define what operational success looks like before the pilot begins, not after it stalls. A 2026 Forbes analysis of the 10-20-70 principle puts the point plainly: 10% of AI success comes from the algorithm, 20% from the data and technology, and 70% from people, process, and organizational change. Most enterprise AI implementation plans invert those proportions.
For CIOs evaluating their current enterprise AI deployment pipeline, the practical implication is a shift in how pilots are scoped. Before a pilot advances, four questions need clear answers:
- Is the data production-ready? Validate data quality, consistency of definitions, and pipeline reliability against live operational conditions before model development advances.
- Does the workflow actually support this? Map the existing process from the perspective of the people who do the work. Every handoff point, every system the output needs to touch, and every step that would need to change should be identified before launch. If nobody on the team has spent time inside the actual workflow, that gap will surface after launch.
- Who owns this in production? A named business owner, accountable for ongoing performance, must be identified before deployment. Ownership that ends at launch is not ownership.
- What does degradation look like, and how will you catch it? Drift monitoring, performance thresholds, and escalation procedures should be operational from day one.
These are baseline requirements that separate a pilot from a production system.
The Question That Separates AI Experiments From AI Systems
The hospital in the opening had a capable model. What it did not have was an implementation team that understood how physicians actually moved through a shift: which systems they opened, in which order, under what time pressure. That understanding would have required someone to spend time in the workflow before the integration was designed.
That is the question every enterprise AI implementation team needs to answer before a pilot advances: what has to be true about our data, our workflow, and our governance for this to still be running and delivering value 90 days after launch?
Rolls-Royce answered it at the data layer. BMW answered it at the workflow layer. JPMorgan Chase answered it at the governance layer. None of them answered it after the fact. The organizations adding to the 88% of proof of concepts that never reach production are the ones that keep trying to.
.avif)
Frequent Asked Questions
How did JPMorgan Chase scale AI across its organization?
JPMorgan Chase built OmniAI, an internal ML platform that standardizes the entire AI lifecycle across every line of business. The platform enforces model risk tiering and automated drift detection as infrastructure requirements, not optional governance steps. It now supports 450+ use cases in production.
What does production-ready AI mean in an enterprise context?
Production-ready AI means the model, the data pipeline, the integration, and the governance are all designed to hold up under real operational conditions, not just demo conditions. It requires defined ownership, monitoring thresholds, and rollback capability before launch, not as a follow-on project.
How do you know if an AI pilot is ready for production?
A pilot is ready for production when four questions have clear answers: Is the data production-ready under live conditions? Does the workflow support the AI output without added manual steps? Is there a named business owner accountable beyond launch day? Are drift monitoring and escalation procedures operational from day one?
What is the biggest challenge in enterprise AI deployment?
Workflow integration is the most underestimated challenge in enterprise AI deployment. A model that performs accurately in a controlled pilot frequently fails when it meets the actual sequence of steps employees follow to complete a task. If the AI output lands in the wrong place or requires extra steps, adoption collapses regardless of model quality.
Why do most enterprise AI implementations fail to reach production?
Most enterprise AI implementations fail because pilots are designed as experiments, not as the first phase of a production system. Teams optimize for model accuracy while leaving data pipelines, workflow integration, and post-launch ownership unresolved.



.svg)






_0000_Layer-2.png)

