
3 Ways to Achieve Model-to-Mission Fit in Enterprise AI
AI model selection can be tricky. Here are 5 key considerations to keep in mind when evaluating AI models to ensure they fit your enterprise needs.
95% of generative AI pilots yield limited, measurable outcomes because enterprises prioritize hype over alignment, opting for oversized models that don’t align with their data, workflows, or strategic objectives.
Cross-functional governance leads to stronger outcomes. AI-mature organizations are 3.8 times more likely to involve legal experts at the ideation stage of an AI project’s life cycle, helping ensure compliance and reduce risk from the start.
As builder companies face $100 billion in compute costs over five years, enterprises gain more value from smaller, domain-specific models that balance performance and price.
After losing a grandparent, a passenger turned to Air Canada’s chatbot for help understanding the airline’s bereavement fare policy. Grieving and seeking guidance, the passenger was informed that they could apply for a refund within 90 days of purchasing their ticket. The chatbot even linked to Air Canada’s own policy page, which in reality said the opposite.
When the airline later refused to honor the promise, the passenger took the case to Canada’s Civil Resolution Tribunal. The court ruled that Air Canada was responsible for its chatbot’s misinformation and ordered the company to pay about $812 in damages and fees. While that may sound minor, at scale, similar AI missteps can add up quickly.
Just this month, Deloitte agreed to refund part of a $440,000 contract to the Australian government after a generative AI-assisted report was found to contain fabricated references and factual errors. These incidents highlight that even modest AI mistakes can snowball into major financial liabilities, compliance failures, and reputational harm when multiplied across enterprise-scale operations.
These cases weren’t just technical AI mistakes but poor model selection and oversight. Both organizations relied on general-purpose systems in situations that required precision, context, and accountability. They were costly reminders that when AI solutions are not purpose-built or properly governed, even the most advanced systems can lead to serious errors, reputational harm, and financial loss.
The same challenge is emerging in different industries. Research indicates that approximately 95% of generative AI pilots yield limited, measurable outcomes, with many failing to achieve a meaningful impact on profit and loss.
For enterprise leaders, the real differentiator is not how advanced an AI system is but how well it aligns with the mission. The central question, then, is how to do model selection in ML and AI projects to ensure that alignment.
In this article, we’ll explore 3 key factors for achieving model-to-mission fit, building AI systems that drive results, meet compliance standards, and earn stakeholder trust.
Aligning Models to Mission for Better AI Outcomes
Model selection is often associated with comparing the technical details of different model types. However, there is another, equally important aspect: how organizations manage and develop these models to align with their mission, data, and compliance requirements.
For enterprises, achieving model-to-mission fit means ensuring that technology choices reinforce business priorities, governance frameworks, and measurable outcomes. Here’s an overview of three key strategies that help organizations choose and govern AI systems that deliver impact, ensure accountability, and build lasting trust:
- Build for Purpose, Not Popularity: AI systems perform best when their architecture, scale, and data align with the mission. Models fine-tuned for specific domains deliver higher accuracy and lower costs, and by 2027, task-specific models are expected to be used three times more often than general-purpose LLMs.
- Calibrate for Context and Domain Fit: Reliable AI depends on continuous calibration and domain alignment. When models aren’t tuned to current data, they overfit, underfit, and lose accuracy over time. Embedding domain-specific retraining and validation into model selection keeps AI systems trustworthy, efficient, and compliant.
- Integrate AI into Real Workflows: Even the most advanced models fail when they don’t fit how teams actually work. Poor integration creates friction and frustration, contributing to burnout, which affects about 66% of workers in 2025. Aligning AI tools with real tasks and processes ensures they enhance productivity rather than add stress.
Next, we’ll take a closer look at these three strategies for developing AI systems that fit enterprise goals and deliver measurable results.
1. Focus on Fit, Not Hype, in Enterprise AI
Many enterprises adopt oversized AI models simply because they are popular, even when they don’t align with real business needs. The hype around large, general-purpose systems often pushes companies to overinvest in tools that aren’t optimized for their workflows or data.
“A large language model itself is a basic foundation akin to an operating system, but ultimately, developers need to rely on a limited number of large models to develop various native applications. Therefore, constantly redeveloping foundational large models represents an enormous waste of social resources.”
- Robin Li, CEO of Baidu
Li’s point highlights a common pitfall: misaligned model selection can drain resources and limit real-world impact. GPT-4, for example, offers impressive capabilities but comes with steep trade-offs, using nearly 10x the electricity of a typical Google search per query.
Additionally, running ChatGPT-class models can incur costs of around $700,000 per day in compute, with inference expenses often exceeding training costs when scaled to millions of users. Analysts estimate that companies in the “builder” category of AI investment will spend nearly $100 billion over the next five years just to support high-performance AI workloads.
To address these challenges, researchers are turning to model distillation, a technique that compresses large foundation models into smaller, more efficient versions while retaining most of their capabilities.
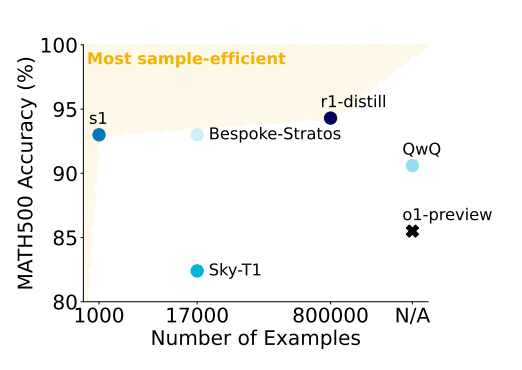
Recently, researchers at Stanford and the University of Washington developed a reasoning model called S1 by distilling Google’s Gemini 2.0 Flash Thinking Experimental model using just 1,000 curated reasoning examples. The process reportedly cost under $50, yet S1 outperformed OpenAI’s o1-preview by up to 27% on math benchmarks such as MATH and AIME24.
As Gartner analyst Haritha Khandabattu explains, “Enterprises have started asking how they can get 80% of the performance at 10% of the cost.”
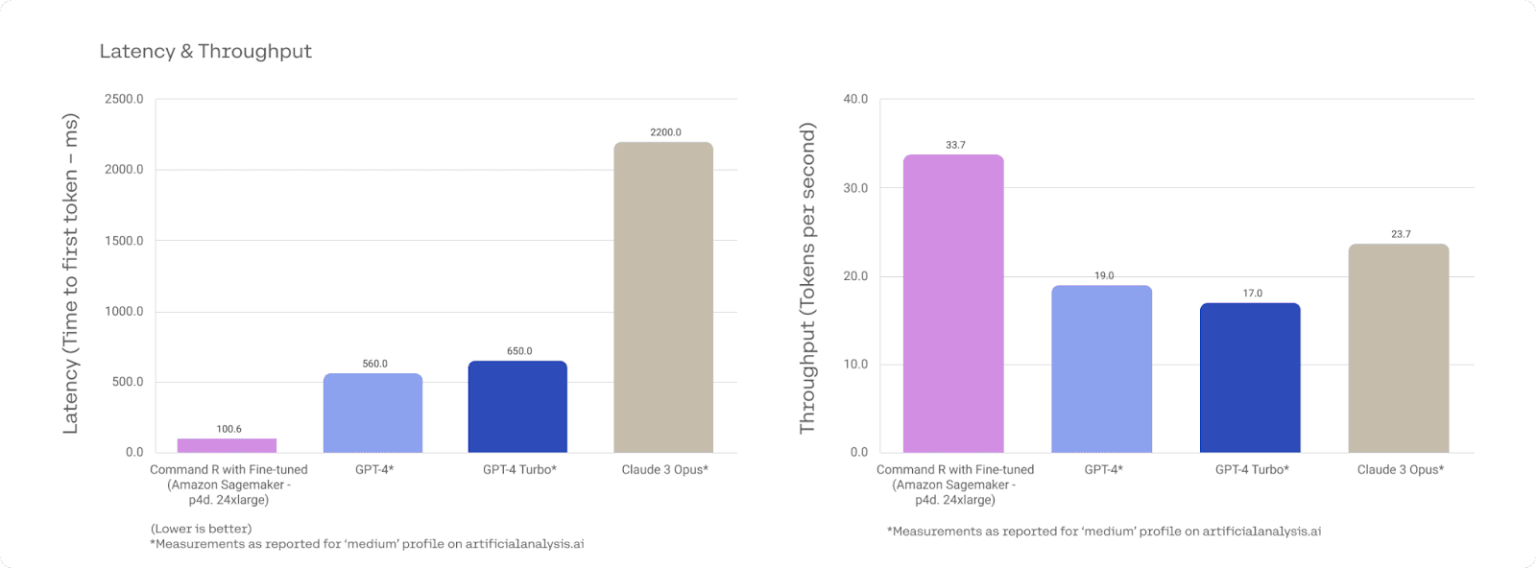
Smaller, domain-specific models also deliver stronger results for targeted tasks. Cohere’s Command R, fine-tuned for meeting summarization and financial or scientific analysis, outperforms GPT-4 at a fraction of the cost.
As Cohere cofounder Nick Frosst notes, “We have found that fine-tuning on data sets with a small model gets really great results.” In benchmark tests, Command R outperforms both GPT-4 and Claude Opus in meeting summarization and financial analysis while remaining significantly more cost-effective to run.
With respect to model selection in machine learning and AI, more popular doesn’t always mean better. Models that align with a company’s workflows and data are the ones that drive real impact.
2. Calibrate for Context: Ensuring AI Models Stay Accurate and Accountable
Reliable AI solutions depend on more than technical sophistication; they require ongoing calibration, domain awareness, and governance discipline. When models are not tuned to real-world data, they lose accuracy and accountability. Underfitting causes models to miss critical patterns; overfitting makes them memorize training data and fail in new contexts. Both lead to wasted investment, compliance exposure, and erosion of trust.
Google’s Flu Trends (GFT) illustrates the risks of poor model generalization. Built to forecast influenza outbreaks from search queries, it overestimated flu prevalence by more than 50% between 2011 and 2013.
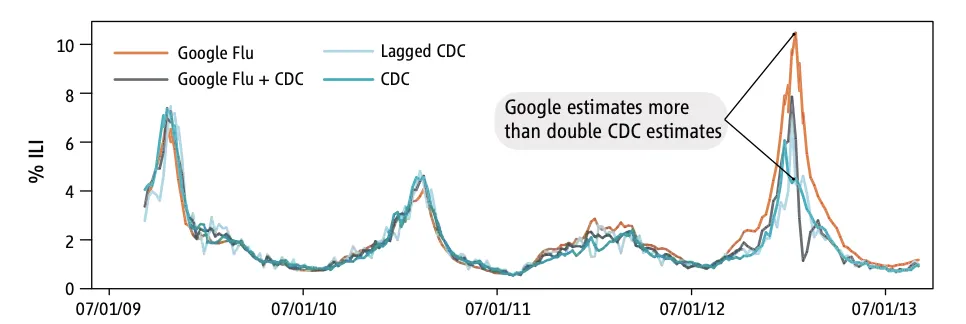
The problem stemmed from trying to match 50 million search terms to just 1,152 CDC data points - a “marriage of big and small data” that produced spurious correlations. The issue was compounded by frequent Google algorithm updates and the “autosuggest” feature, which further distorted inputs.
Without recalibration, the model drifted further as Google’s algorithms evolved, highlighting how weak generalization and poor oversight can compound error.
“GFT was like the bathroom scale where the spring slowly loosens up and no one ever recalibrated.”
- David Lazer of Northeastern University
The same principle applies across industries: AI models perform best when designed for their domain and regularly retrained against ground truth. In biomedicine, for instance, models like PubMedBERT, trained on biomedical literature, outperform general-purpose systems such as GPT-4 on specialized protein–protein interaction tasks.
3. From Silos to Synergy: Embedding AI in Real Workflows
Many AI challenges stem not from weak technology but from fragmented workflows. When model selection and deployment are handled in isolation, by IT, data science, or business teams alone, AI systems often fail to integrate smoothly into daily operations. The result is redundant work, slow adoption, and missed opportunities for impact.
Although 78% of organizations utilize AI in at least one business function, most still struggle to embed it across their teams effectively. Projects that bring together data, business, and operations leaders from the start are far more likely to deliver measurable results. Cross-functional alignment ensures that models are designed around real processes, not abstract technical goals.
AI-mature organizations are a clear example of this difference. They are 3.8 times more likely to engage legal counsel at the ideation stage, ensuring that compliance, fairness, and risk management are built in from the outset. By doing so, they integrate business requirements directly into model development and automate workflows end-to-end - reducing friction, improving compliance, and accelerating scale.
Equally important is the role of governance in sustaining AI automation. Well-structured governance transforms automation from a technical initiative into a scalable, trusted capability that supports both compliance and business agility.
As Seb Burrell, Head of AI at Trustmarque, notes, “It’s a clear gap; 93% of organizations are using AI, but only 7% have fully embedded governance frameworks.” Closing that gap begins not with more rules, but with collaboration that connects AI systems to the workflows they are designed to enhance.
Thoughtful Model Selection Builds Reliable AI Solutions
Air Canada’s chatbot failure illustrates how misaligned AI models can turn small mistakes into costly liabilities. When systems lack calibration, oversight, and domain alignment, even advanced technology can produce errors that damage trust, compliance, and reputation.
Enterprises can avoid these AI mistakes by prioritizing the selection of fit-for-purpose models. Choosing models that are tuned to their domain, regularly retrained to prevent overfitting and underfitting, and integrated into real workflows ensures AI delivers measurable value, efficiency, and long-term ROI.
.avif)



.svg)






_0000_Layer-2.png)

